介绍
本文分析了pytorch中dataloader类里num_workers参数最合理的设置方法。
测试代码
from time import sleep
from timeit import default_timer
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader, Dataset
class SleepDataset(Dataset):
def __getitem__(self, item):
sleep(1)
return 1
def __len__(self):
return 20
def run_batch(batch):
batch[0] += 1
sleep(0.25)
def test_iter(dataloader: DataLoader):
batch_time = []
start = default_timer()
for batch in dataloader:
run_batch(batch)
batch_time.append(default_timer() - start)
start = default_timer()
print([f'{j:.2f}' for j in batch_time])
return batch_time
if __name__ == '__main__':
all_batches = []
for i in range(5):
sleep_dataloader = DataLoader(SleepDataset(), batch_size=1, num_workers=i)
all_batches.append(test_iter(sleep_dataloader))
for i, batch in enumerate(all_batches):
plt.plot(batch, label=f'{i}')
plt.legend()
plt.show()
输出
在具有40核的服务器上运行代码,命令行输出如下所示
['1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25', '1.25']
['1.27', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00', '1.00']
['1.27', '0.25', '0.75', '0.25', '0.75', '0.25', '0.75', '0.25', '0.75', '0.25', '0.75', '0.25', '0.75', '0.25', '0.75', '0.25', '0.75', '0.25', '0.75', '0.25']
['1.27', '0.25', '0.25', '0.50', '0.25', '0.25', '0.50', '0.25', '0.25', '0.50', '0.25', '0.25', '0.50', '0.25', '0.25', '0.50', '0.25', '0.25', '0.50', '0.25']
['1.28', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25', '0.25']
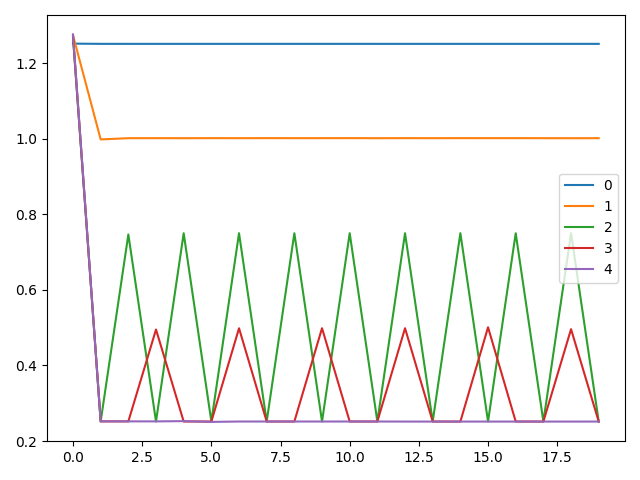
输出图片为
分析
首先分析num_workers为0的情况,该情况最为简单,对于每个batch,先由dataloader读取,耗时1s,之后进行数据处理,在run_batch函数中,耗时0.25s,共计耗时1.25s。如果是用来训练,这样的表现会带来一个问题,即在GPU中训练模型时,CPU一般是空闲的,最好可以用来后台加载数据。
可以看到,设置num_workers等于1时,现象明显有所改善,这是因为此时从主进程中单独复制出一个进程,用来后台读取数据,如果该进程读取的数据被使用,则会自动进行下次读取。主循环中读取第一个batch用了1.27s,这是复制进程的开销,读batch的时间加处理batch的时间,第一个batch被消耗后,后台进程自动读取第二个batch,注意到开始读第二个batch是在处理batch之前发生的,而且读batch要比处理batch耗时,所以读取第二个batch需要额外的0.75s,以及处理batch的0.25s,共计耗时1s,之后的情况与此相同,依次类推。
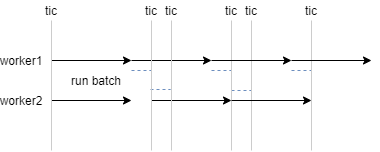
设置num_workers为2时,读取数据的时间开始出现波动,程序运行的时间线如下图所示。需要注意的是,num_workers为2时,是创建两个进程,分别读取一个batch,而不是两个进程共同读取一个batch。图中蓝色虚线表示消耗数据,黑色箭头表示读取数据,灰色实线表示计时点。可以看到,第一个batch被读取加消耗共计耗时1.25s,第一个batch开始被处理时,worker1已经开始读取第三个batch。第一个batch被消耗后,因为第二个batch已经读取完成,所以直接被消耗,仅耗时0.25s,但消耗第三个batch时需要等待读取,需要额外等待0.5s,因此第二个batch和第三个batch间间隔0.75s,之后的情况以此类推。
设置num_workers为3的情况与设置为2的情况类似,不过因为num_workers的数量增大,减小了等待时间。
观察到设置num_workers为4时,程序达到了理论最优速度,因为处理每个batch需要0.25s,而程序的耗时也极为接近为0.25s,超出的部分应该为进程开销,可忽略。显然,此时是因为有充足的worker来预读取数据,使得run_batch不需要等待io。显然,当num_workers设置为更大的值时,程序不能进一步提速。
num_workers设置指南
首先值得注意的是,本文仅模拟了CPU bounded的情况,没有模拟IO bounded的情况。
根据上文实验,结合理论推导,我们假设CPU读取每个batch需要m秒,处理每个batch需要n秒,有x个workers同时工作,GPU,即run_batch函数处理每个batch需要y秒,则整个循环中,每个batch被处理的时间t=max(m+n/x, y)。因此我们可以设置m+n/x=y,即如果y大于m,则设置x=n/(y-m)。如果y小于m,则设置为cpu的数量,以减小数据处理的时间。
根据上文分析,似乎将num_workers一直设置为CPU数量也无影响,从理论分析来看,在平均运行时间上确实似乎无影响,但当程序是IO bounded时,第一个batch开始被处理的时间,完全正比于num_workers,而且设置过大可能会导致内存溢出的问题。